为学习spark,虚拟机中开4台虚拟机安装spark3.0.0
底层hadoop集群已经安装好,见ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境
首先,去http://spark.apache.org/downloads.html下载对应安装包

解压
[hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local [hadoop@master ~]$ cd /usr/local [hadoop@master /usr/local]$ sudo mv ./spark-3.0.0-bin-without-hadoop/ spark [hadoop@master /usr/local]$ sudo chown -R hadoop: ./spark
四个节点都添加环境变量
export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置spark
spark目录中的conf目录下cp ./conf/spark-env.sh.template ./conf/spark-env.sh后面添加
export SPARK_MASTER_IP=192.168.168.11 export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_LOCAL_DIRS=/usr/local/hadoop export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后配置work节点,cp ./conf/slaves.template ./conf/slaves修改为
master
slave1
slave2
slave3
写死JAVA_HOME,sbin/spark-config.sh最后添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
复制spark目录到其他节点
sudo scp -r /usr/local/spark/ slave1:/usr/local/ sudo scp -r /usr/local/spark/ slave2:/usr/local/ sudo scp -r /usr/local/spark/ slave3:/usr/local/ sudo chown -R hadoop ./spark/
...
启动集群
先启动hadoop集群/usr/local/hadoop/sbin/start-all.sh
然后启动spark集群

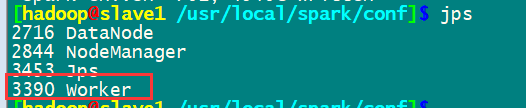
通过master8080端口监控

完成安装
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
暂无评论...
更新日志
2024年05月20日
2024年05月20日
- 崩坏星穹铁道梦中之梦12平民满星攻略 梦中之梦12阵容搭配分享
- 钟志刚《淡淡君情》24K金限量头版[低速原抓WAV+CUE]
- 金山游戏封神再临视频首曝 预计年内上线
- IGN分享PC《对马岛之魂》28分钟实机:极致的画面表现
- 钟明秋《是时候HQ》头版限量编号[低速原抓WAV分轨]
- 蜀门手游五月大服龙城飞将开启 全新大逃杀玩法上线
- 崩坏星穹铁道平民神主日怎么打 神主日萌新通关攻略
- 赵传《我是一只小小鸟》日本东芝1A1版 [WAV+CUE][435M]
- 庄达菲《东张西望》[320K/MP3][40.28MB]
- 庄达菲《东张西望》[24bit 48kHz][FLAC/分轨][288.46MB]
- 金海心.-.[心感觉].专辑[原抓WAV+CUE]
- KOKIA心は?かり(2012K2HD2016Mora)[24bit96kHzFLAC]
- 林一峰2017-绝对清白2CD[香港首版][WAV+CUE
- 石凯《数星一整夜》[320K/MP3][44.18MB]
- 石凯《数星一整夜》[24bit 48kHz][FLAC/分轨][395.49MB]